This blog was first published on Arm's Community website on October 13, 2020.
We live in a world of data. Virtually everyone talks about data and the potential value we can extract from it. Massive amounts of raw data is complex and hard for us to interpret and, over the past few years, machine learning techniques have made it possible to better understand this data and leverage it to our benefit. So far, most of the value has been realized by online businesses, but now the value is also starting to spread to the physical world where the data is generated by sensors. For many, however, the path from sensor data to an embedded AI model seems almost insurmountable.
Writing embedded software is notoriously time consuming, and is known to take at least 10-20 times longer than desktop software development [1]. It doesn’t have to be that way. Here, we’ll walk you through a real Edge AI project—from data collection to embedded application—using our efficient, time-saving method.
Machine Learning on the Edge
Today, the vast majority of software for processing and interpreting sensor data is based on traditional methods: transformation, filtering, statistical analysis, etc. These methods are designed by a human who, referencing their personal domain knowledge, is looking for some kind of “fingerprint” in the data. Quite often, this fingerprint is a complex combination of events in the data, and machine learning is needed to successfully resolve the problem.
To be able to process sensor data in real time, the machine learning model needs to run locally on the chip, close to the sensor itself—usually called “the edge.” Here, we will explain how a machine learning application can be created, from the initial data collection phase to the final embedded application. As an example, we will look at a project we at Imagimob carried out together with the radar manufacturer Acconeer.
Embedded AI project: Gesture Recognition

In 2019, Imagimob teamed up with Acconeer to create an embedded application with gesture recognition. Both companies focus on providing solutions for small battery-powered devices, with extreme requirements on energy efficiency, processing capacity, and BOM cost. Our target hardware contains an MCU based on the Arm Cortex M0 – M4 architecture, which provides the most energy efficient platforms on the market. For us at Imagimob, edge computing has almost become synonymous with advanced computing on the smallest Arm Cortex M-series MCUs. It is important to be able to run our applications on the lower end of Arm Cortex M-series MCUs since it signals to the world that we are targeting the smallest devices on the planet. And that’s where we want to be from a market perspective.
Acconeer produces the world’s smallest and most energy efficient radar system. The data contains a lot of information, and for advanced use cases, such as gesture control, complex interpretation is needed. These cases benefit greatly from having machine learning software running on top of the data output stream. The Imagimob-Acconeer collaboration is, therefore, a good match when it comes to the creation of radically new and creative embedded applications.
The goal for our project with Acconeer was to create an embedded application that could classify five different hand gestures in real time using radar data (including one gesture used to wake up the application). With its small size, the radar could be placed inside a pair of earphones, and the gestures would function as virtual buttons to steer the functionality, which is usually programmed into physical buttons. The end product for the project was determined to be a C library running on an Arm Cortex M4 architecture, which was shown as a robust live demo at CES in Las Vegas in January 2020. For the demo, we used on-ear headphones. However, our long-term product goal is to use this technology in in-ear headphones. We believe that gesture detection especially makes a difference in the usability of in-ear headphones, due to their restricted amount of area which makes the placement of physical buttons difficult.
From Data Collection to Embedded C Library
At its core, (supervised) machine learning is about finding a function (f) that maps some input data (x) to some output data (y), according to y = f(x). The function, or “model,” is found by processing many different input-output pairs (x, y) and “learning” their relationship. If y is a continuous value, the problem is said to be a regression problem. But if y takes on discrete values, then it is considered a classification problem. The first step in a machine learning project is therefore to collect these data pairs. Model building is the second step. And the last step for embedded projects is to deploy the model on a target platform. Below, we will go through these steps using the gesture recognition project as a guiding example.
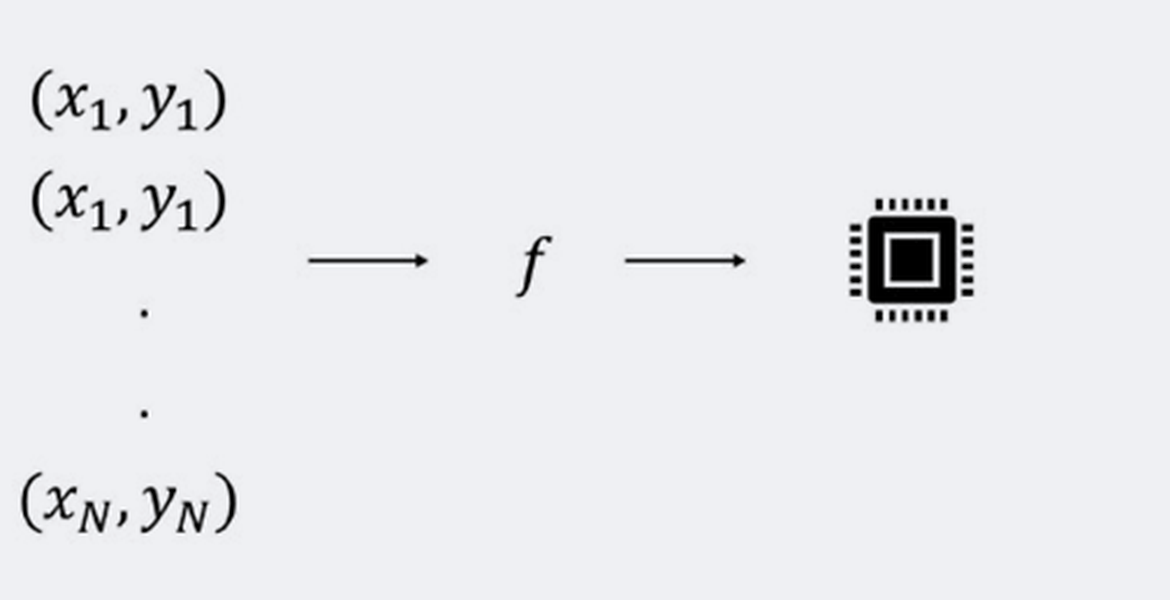
1 Data collection
On the surface, data collection may not seem like a difficult task. But this step is usually underestimated and, in our experience, this is where much of the time is spent. The first thing to consider is how to physically get the data out from the sensor. Many sensors come with a development board from which data can be extracted, often via some kind of cable connection to a PC. For the gesture recognition project, we built a rough test rig for the initial data collection consisting of the radar sensor mounted on the development board and placed on a pair of headphones, as shown in the image below. In this case, we used the Acconeer XM112 radar sensor and the XB112 breakout board.
The next thing to consider is how the data can be efficiently labeled. In other words, you need to figure out how to mark the appropriate “y” for each “x.” This may seem trivial, but it is crucial when it comes to minimizing the amount of manual work this step will require. Given the large amount of data, if you don’t get this right, it will become a very time-consuming task. For sensor time series data, it is usually impossible to label the data just by looking at it, which may otherwise be possible with, e.g., image data.
One way to aid the labelling process is by having a video recording attached to the data. Imagimob Capture is an Android app that attaches a time-synched video recording to each sensor data stream. Labelling can be done either directly in the app or later on in the desktop app Imagimob Studio. In the case of our radar gesture recognition project, the data flow looked like the following:
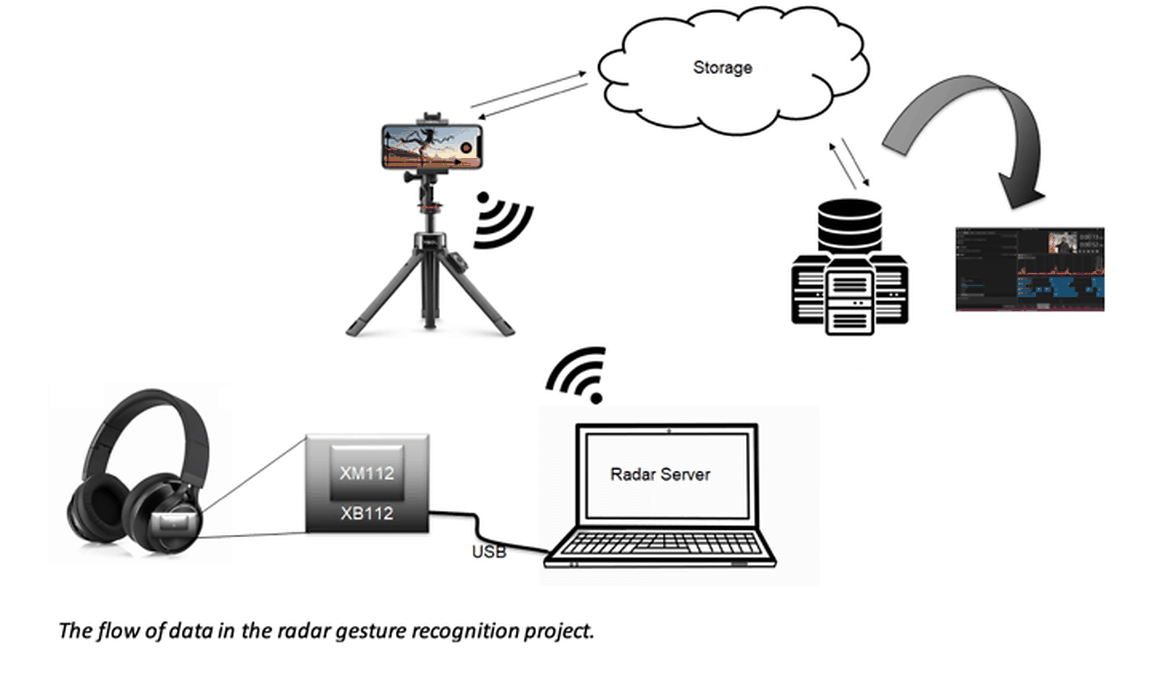
Here, the data is sent from the sensor, via the USB serial port, to a PC. On the PC, a server runs and sends the data to Imagimob Capture on a mobile phone, while the gesture is being video recorded. The labeled data, together with its video recording, is then sent back to the PC, or to a cloud storage if data is being collected remotely. From the storage, the data can be downloaded to Imagimob Studio, when it is time for the modeling phase.
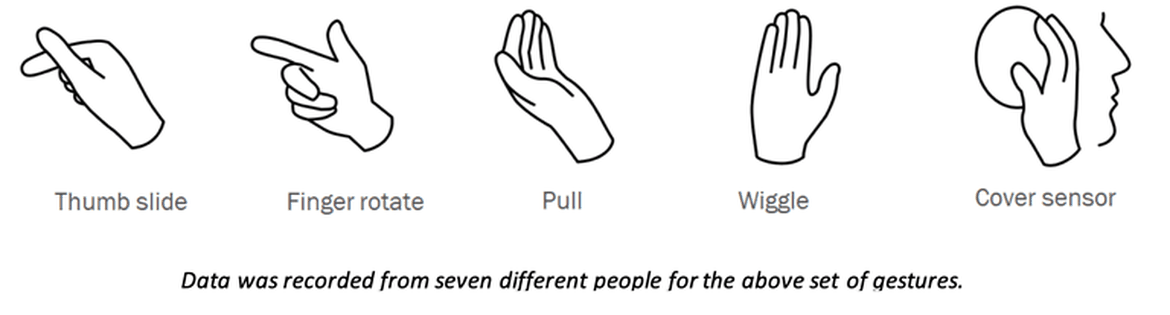
We defined the following set of gestures (“Cover sensor” is only used to wake up the application) and recorded data from roughly seven different people. The gesture recognition model is currently limited to these specific gestures, but can easily be retrained with other gestures.
2 Modelling
Once the data is in place and labelled, it’s time to build a machine learning model. In many cases, people start building a model only to soon realize that they need to adjust some of the labels. What do you do? It is cumbersome to manually go in and edit text files and update the data, something we would all like to avoid as much as possible. Rather, a graphical tool is desirable. Imagimob Studio loads the data together with the video recording and lets users drag and trim the labels graphically. An example, featuring one of the recorded gestures, is shown in the image below. The video is visible together with the data in green. At the bottom, the labels in blue are shown and we can see that they are tightly placed around the gesture (the non-zero data).
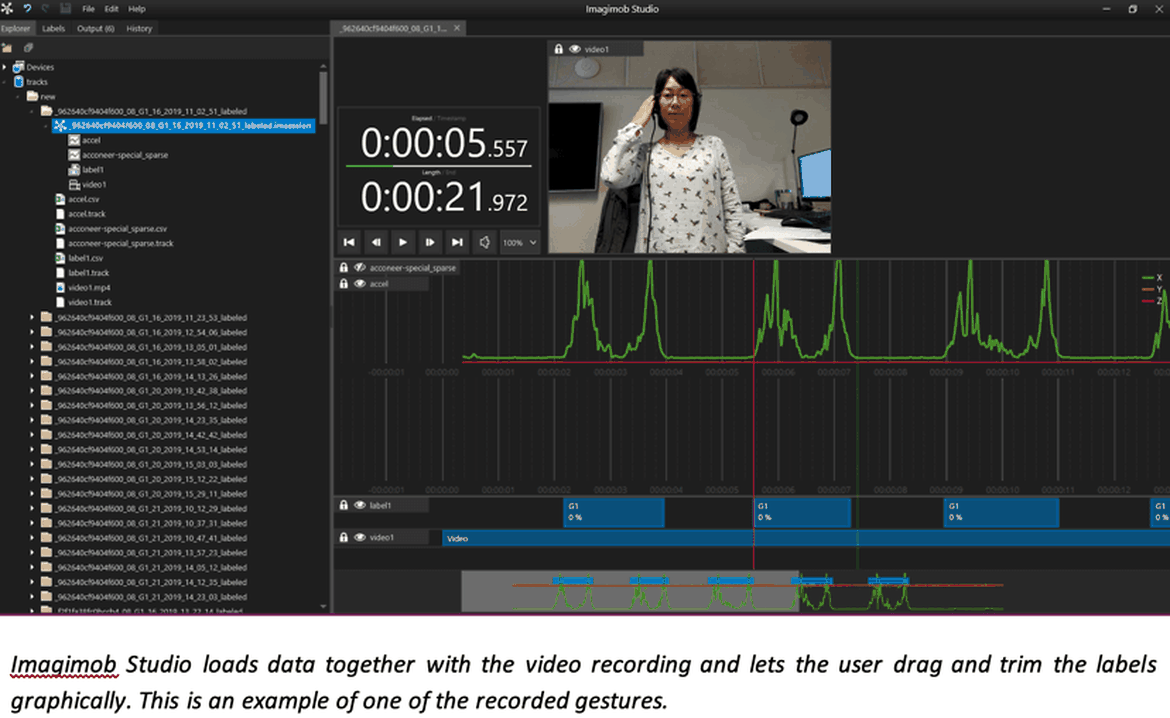
If the data is already pre-labeled in Imagimob Capture, it is a relatively small task to go through the files and make sure the data is correct and that the labels are in place. Without correctly labeled data, it will be difficult to find a good model. Finding a good model with high accuracy usually involves many iterations and experiments. The first thing to decide is what machine learning technique to use, e.g., random forests, support vector machines or artificial neural networks, among others. In the past few years, deep learning has gained popularity due to the impressive learning capabilities with raw data. One of the main attractions of deep learning is that it excludes the need of manually finding features which is required in more traditional machine learning approaches. It has both the potential to increase accuracy and eliminate a lot of the manual work. However, there are still many so-called hyperparameters left to be chosen, e.g., the architecture of the network, so-called learning rate, and many others. In Imagimob Studio, users are guided through the process of building a deep neural network, as shown below. The user defines how many different types of hyperparameters to try out, then the program automatically searches through all the combinations and saves the best model.
Once you are happy with the robustness of the model, it is time for the final step in the process: Exporting the model to C code and building a library for the embedded hardware.
3 Deployment
When going from software development in high-level languages in a PC environment to lower-level programming on microcontrollers (MCUs), there is a sharp increase of complexity. Development time increases in factors of 10-20 are not uncommon [1]. The hurdles can in include, for example, harder memory and processing restrictions, longer debugging cycles, and nastier types of bugs which are harder to find.
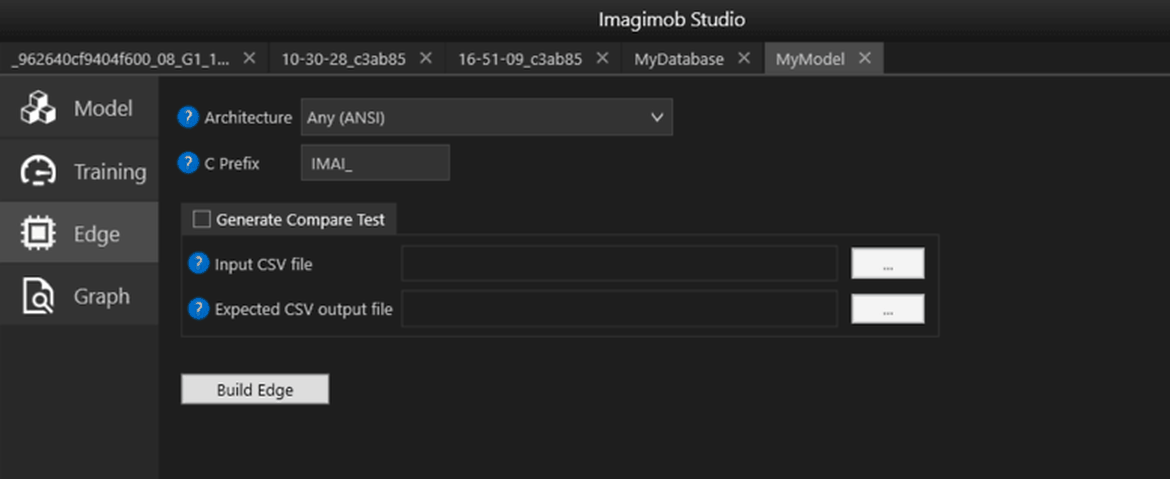
In Imagimob Studio, a trained model in the form of a .h5 file (a common format used to export model weights and architectures from Tensorflow, Keras, and other deep learning frameworks) can be easily translated to C code for a specific hardware type, as shown on the “Edge” tab in the image above.
The C code is then compiled and flashed to the hardware. We usually build a library that can be integrated into a C application. It has a battery driven Acconeer IoT module XM122 with a bluetooth connection. The AI application runs on the XM122 module, which includes an NRF 52840 SoC from Nordic Semiconductors which is based on an Arm Cortex M4 MCU.
Imagimob Gesture Detection Library Specifications
At its core, the Imagimob Gesture Detection Library is composed of an artificial neural network targeted to time series data. It is specifically designed with a small memory footprint in mind. The library is written in C and compiled in a static library, which is then compiled together with the main Acconeer C application.
· The Gesture detection library uses radar data from the Acconeer XM122 IoT Module as input
· The memory footprint of the gesture library is approximately 80 kB RAM
· The library runs on a 32-bit 64 MHz Arm Cortex M4 MCU with 1 MB Flash and 256 kB RAM
· The library processes roughly 30 kB of data per second
· The execution time of the AI model is roughly 70 ms which means that it predicts a gesture at approximately 14.3 Hz
The Next Step: Gesture-controlled In-ear Headphones
In June 2020, a consortium consisting of Imagimob, Acconeer, and Flexworks received a grant worth $450,000 from Swedish Vinnova to take the next step in building gesture-controlled in-ear headphones. Acconeer will cover the sensing part, Flexworks will be responsible for hardware and mechanics, and we at Imagimob will develop the gesture detection application. In this project, not only will we build the first gesture-controlled in-ear headphones, but we will also work towards a hardware accelerated system for the machine learning code on the MCU. We will continue to use the Arm Cortex M series and benefit from the advanced solutions provided by Arm.
Johan Malm, Ph.D. is a specialist in numerical analysis and algorithm development. He works as a machine learning developer at Imagimob.
References
[1] McConnell, Steve, Software Estimation, Demystifying the Black Art, Microsoft Press, 2006