
If you’ve noticed a surge of AI powered products and services hitting the marketplace lately, you are not mistaken. Artificial Intelligence (AI) and machine learning (ML) technology have been developing rapidly in recent years, with possibilities growing in tandem with a greater availability of data and advancements in computing capability and storage solutions.
In fact, if you look behind the scenes, you can spot many examples of ML technology already in practice in all kinds of industries—ranging from consumer goods and social media to financial services and manufacturing.
But the question remains: How did ML evolve from science fiction to reality in such a short period time? After all, it was only in 1959 that data scientist Arthur Lee Samuel successfully developed a computer program that could teach itself how to play checkers.
To find the answer, let’s chart the course of machine learning’s development by taking a look at the past and present, and envisioning what might be coming next.
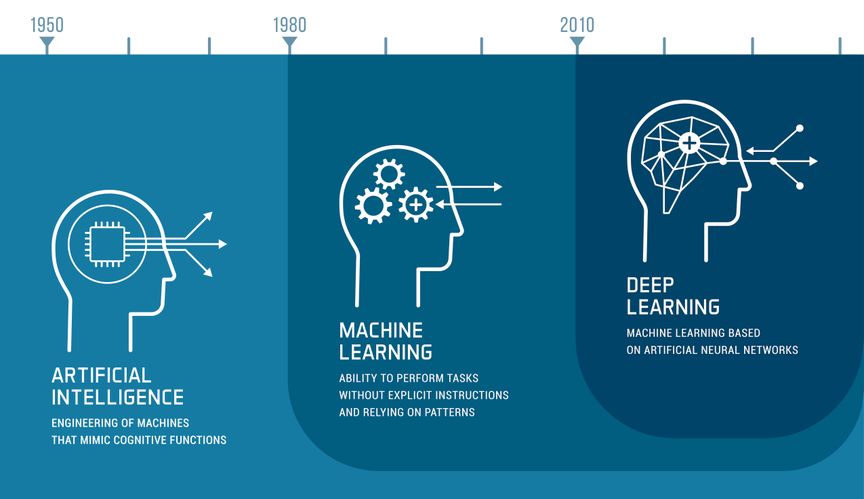
Machine learning (ML) is a sub-set of AI where machines, enabled with trained algorithms and neural network models, are able to autonomously learn from data and continuously improve performance and decision making accuracy related to a specific task.
The origin of ML can be traced back to a series of profound events in the 1950s in which pioneering research established computers’ ability to learn. In 1950, the famous “Turing Test” was developed by the English mathematician Alan Turing to determine if a machine exhibits intelligent behavior equal or similar to a human.
In 1952, the data scientist Arthur Lee Samuel managed to teach an IBM computer program to not only learn the game of checkers but to improve the more it played.
Then in 1957, the world’s first neural network for computers was designed by the American psychologist Frank Rosenblatt. From there, experimentation escalated.
In the 1960s, Bayesian methods for probabilistic interference in machine learning were introduced. And in 1986, the computer scientist Rina Dechter introduced the Deep Learning technique, based on artificial neural networks, to the machine learning community.
It wasn’t until the 1990s that ML shifted from a knowledge-driven approach to the data-driven approach we are familiar with today. Scientists started creating computer programs that could analyze large quantities of data and learn from the results.
It was during this period that support vector machines and recurrent neural networks rose in popularity. In the 2000s, Kernal methods for algorithm pattern analysis, like Support Vector Clustering became prominent.
The next momentous event that helped enable machine learning as we know it today is hardware advancements which occurred in the early 2000s.
Graphics processing units (GPUs) were developed that could not only speed up algorithm training significantly—from weeks to days— but could also be used in embedded systems.
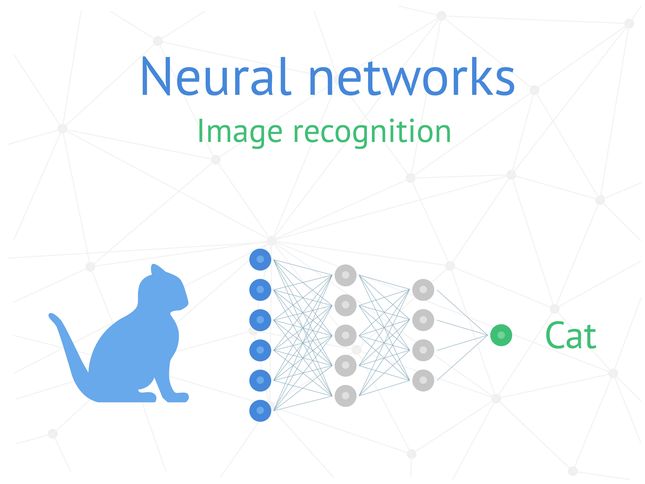
In 2009, Nvidia’s GPUs were used by the famous Google Brain to create capable deep neural networks that could learn to recognize unlabeled pictures of cats from YouTube.
Once deep learning became demonstrably feasible, a promising new era of AI and machine learning for software services and applications could begin.
Today, the demand for GPUs continues to rise as companies from all kinds of industries seek to put their data to work and realize the benefits of AI and machine learning.
Some examples of machine learning applications we can see today are medical diagnosis, machine maintenance prediction, and targeted advertising.
However, when it comes to applying ML models in the real world, there’s a certain stumbling block that is hindering progress. And that stumbling block is called latency.
Most companies today store their data in the cloud. This means that data has to travel from edge devices to the cloud —which is often located thousands of miles away—for model comparison before the concluding insight can be relayed back to the edge devices. This is a critical, and even dangerous problem in cases such as fall detection where time is of the essence.
The problem of latency is what is driving many companies to move from the cloud to the edge today. “Intelligence on the edge,” Edge AI” or “Edge ML” means that, instead of being processed in algorithms located in the cloud, data is processed locally in algorithms stored on a hardware device, ie at the edge.
This not only enables real-time operations, but it also helps to significantly reduce the power consumption and security vulnerability associated with processing data in the cloud.

As we move towards applying AI and edge ML to smaller and smaller devices and wearables, resource constraints are presenting another major roadblock. How can we run Edge ML applications without sacrificing performance and accuracy?
While moving from the cloud to the edge is a vital step in solving resource constraint issues, many ML models are still using too much computing power and memory to be able to fit the small microprocessors on the market today.
Many are approaching this challenge by creating more efficient software, algorithms and hardware. Or by combining these components in a specialized way.
So what’s next? The future of ML is continuously evolving, as new developments and milestones are achieved in the present. While that makes it challenging to offer accurate predictions, we can, however, identify some key trends.
A number of existing platforms for Edge ML include smart speakers like Amazon’s Echo and Google’s Home. In the energy and industrial space, some companies have developed Edge ML systems with predictive sensors and algorithms that monitor the health of the components to notify technicians when maintenance is required. Other Edge ML systems monitor for emergencies like machine malfunctions or meltdown.
In the future, there is talk about developing Edge ML based systems in healthcare and assisted living facilities to monitor things like patient heart rate, glucose levels, and falls (using radar sensors, cameras and/or motion sensors). These technologies could be life-saving and, if the data is processed locally at the edge, staff would be notified in real-time when a quick response would be essential for saving lives.

Working with Edge ML applications has opened up a new world of possibilities for developing highly sustainable solutions. These Edge ML applications has resulted in portable, smarter, energy-efficient, and more economical devices. Edge ML can be used to help manage environmental impacts across a variety of applications e.g clean distributed energy grids, improved supply chains, environmental monitoring, agriculture applications as well as improved weather and disaster predictions.
Data centres consume an estimated 200 terawatt hours (TWh) of energy each year–more than the energy consumption of some countries. They also produce an estimated 2% of all global CO2 emissions. This means that Edge ML can help reduce power consumption in data centres.
In the majority of AI and ML projects today, the tedious process of sorting and labelling data takes up the bulk of development time. In fact, the analyst firm Cognilytica estimated that in the average AI project, about 80% of project time is used aggregating, cleaning, labeling, and augmenting data to be used in ML models.
This is why the prospect of unsupervised learning is so exciting. In the future, more and more machines will be able to independently identify previously unknown patterns within a data set which has not been labelled or categorized.
Unsupervised learning is particularly useful for discovering previously unknown patterns in a data set when you do not know what the outcome should be. This could be useful for applications such as analyzing consumer data on edge devices to determine the target market for a new product or detecting data anomalies like fraudulent transactions or malfunctioning hardware.
A new generation of purpose-built accelerators is emerging as chip manufacturers and startups work to speed up and optimize the workloads involved in Edge ML projects—ranging from training to inferencing at the edge. Faster, cheaper, more power-efficient and scalable. These accelerators promise to boost edge devices and Edge ML systems to a new level of performance.
One of the ways they achieve this is by relieving edge devices’ central processing units of the complex and heavy mathematical work involved in running deep learning models. What does this mean? Get ready for faster predictions.
Companies such as Arm, Synaptics, Greenwaves, Syntiant and many others are developing edge ML chips that are optimised for performance and low power consumption at the edge.
In the future, the much talked about Internet of Things will become increasingly tangible in our everyday lives. Especially as AI and ML technology continues to become increasingly affordable. However, as the number of edge ML devices increase, we will need to ensure we have an infrastructure to match. According to Drew Henry, Senior Vice President of Strategy Planning & Operations at Arm in a recent article:
“The world of one trillion IoT devices we anticipate by 2035 will deliver infrastructural and architectural challenges on a new scale…our technology must keep evolving to cope. On the edge computing side, it means Arm will continue to invest heavily in developing the hardware, software, and tools to enable intelligent decision-making at every point in the infrastructure stack. It also means using heterogeneous [computation] at the processor level and throughout the network—from cloud to edge to endpoint device.”
When we look at history and where we are today, it appears that the evolution of edge ML is fast and unstoppable. As future developments continue to unfold, prepare for impact and make sure you're ready to seize the opportunities this technology brings.